
Hw2
Movie Recommendations based on IMDB Scraping
For this project, I am creating a scraper for the movie, Catch Me if You Can, and providing recommendations based on movies that share the actors from Catch Me if You Can.
First Parse Method - Movie Page
The method starts on the movie page and navigates to the full credits page
- After creating the class and saving the movie page’s url as a list, define the first parse method
- Index into the zero index of the movie url list and add “fullcredits”, save this in a variable
- Yield a request object that executes on the variable made in step 2. It’s callback argument takes in the following parse method.
class ImdbSpider(scrapy.Spider): name = 'imdb_spider' start_urls = ['https://www.imdb.com/title/tt0264464/'] def parse(self, response): cast_crew = self.start_urls[0] + "fullcredits" yield scrapy.Request(cast_crew, callback= self.parse_full_credits)
Second Parse Method - Full Credits
This method will navigate from the full credits page to each actor’s page
- Create a list comprehension that will run a relative path for each actor, save it to the variable actor_path
- Create a prefix variable for https://www.imdb.com/ 3, Create an acot_urls variable that adds to the prefix and will run a for loop through actor_paths, this mimics clicking on the actor headshots
- Create a for loop that indexes through actor_urls and yield a request object with a callback argument for the next parse method
def parse_full_credits(self, response):
actor_path = [a.attrib["href"] for a in response.css("td.primary_photo a")]
prefix = "https://www.imdb.com"
actor_urls = [prefix + suffix for suffix in actor_path] #clicking on actor headshot to go to actor page
for info in actor_urls:
yield scrapy.Request(info, callback = self.parse_actor_page)
Third Parse Method - Actor Page
This method will attain the actor’s name and their movies.
- Create a response.css object to get the actor name
- Create a for loop through a response.css object that contains the actor’s movies and will iterate through this list of movies
- Inside of the for loop create a response.css object that gets all the names of the movies
- yield a dictionary that holds the actor’s name and the movies they have been in
def parse_actor_page(self, response):
actor_name = response.css("span.itemprop::text").get() #actor name
for movie in response.css("div.filmo-row b a::text").getall(): #get all the names of the movies the actor was in
yield{
"actor": actor_name,
"movie" : movie
}
Recommendation
By using pandas on the csv file attained from the scraper, we can see what movies have the most shared actors with Catch Me if You Can.
impot pandas as pd
data = pd.read_csv("results.csv")
topten = data.groupby("movie").count() #group the data by the movies
topten = topten.sort_values(by = "actor", ascending= False).head(10) #sort and show the data based on what movies have the most shared actors
topten
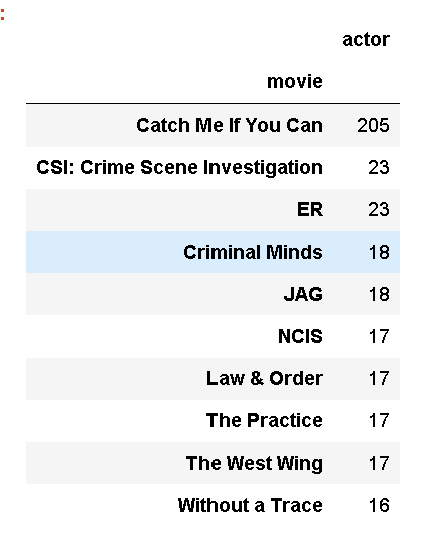
topten.plot.bar()
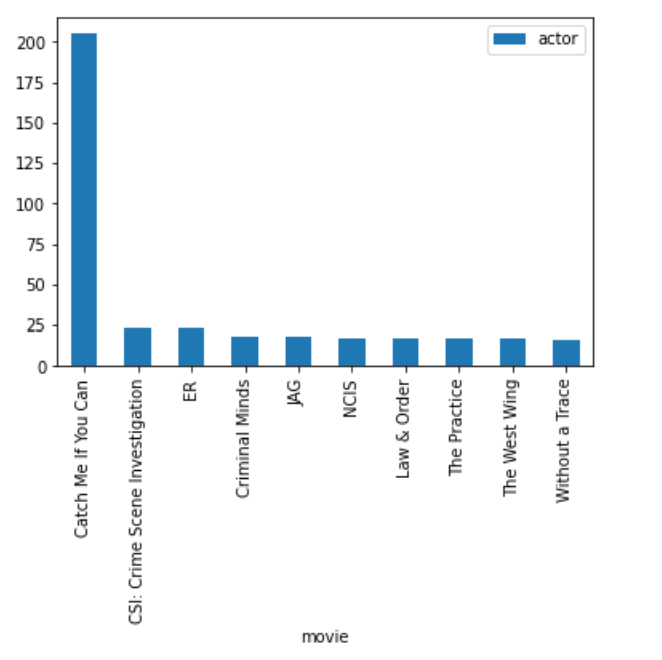
If you like the movie, Catch Me if You Can, these are 10 other movies you might like based on the shared actors
Written on May 1, 2022