Scotus opinion project
Overview
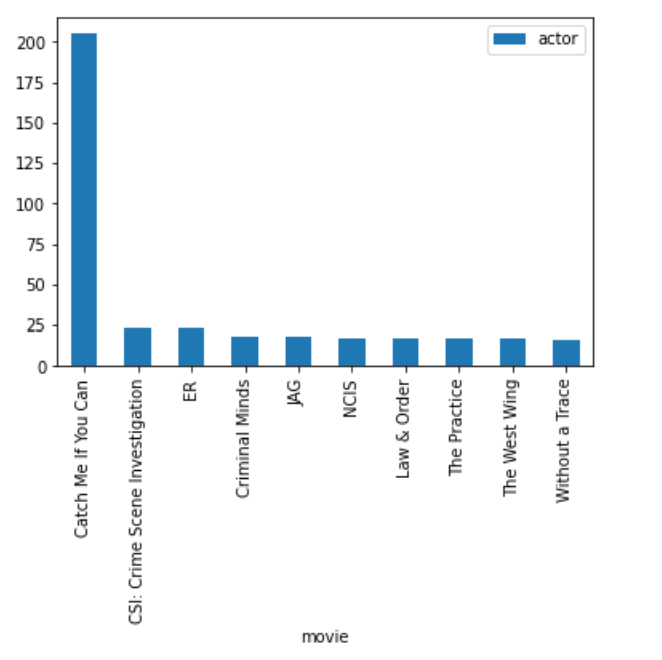
For our project, we conducted a sentiment analysis on the opinions of Supreme Court Justices with the aim to differentiate and highlight the unique “legal writing styles” of the Justices, which is beneficial for people learning about legal writing and may reveal Justices’ legal philosophy. Our methodology included downloading large volumes of Supreme Court opinion PDFs from the official website. Then, we used OCR tools to detect and store the text before using regular expressions to separate the opinions and identify the author in order to construct our official dataset CSV. After preparing the data, we utilized NLP packages and tensorflow in order to find high prevalence words for each opinion type and author, as well as score the overall sentiment in the opinion. Once we created our models for both type and author classification based on the text, we tested these models on completely unseen data from the past 2 months. After examining our results, which were poor on the unseen data, we attempted to recreate our models after removing the justices from the training set who were not seen in the test set. As a result, our results seemed to improve.

Technical Components
Web Scraping OCR/Text Cleaning Type and Author Classification Retraining the Data and repeating Testing
Web Scraping
We began by scraping the Supreme Court Opinions Directory which contained pdf links of the Supreme Court opinions from 2021 to 2014. To create the scraper, we made a parse method that used the relevant css selectors and tags to acquire the opinion PDF links for each month of the year. Next we utilized a for loop to index through the list of PDF links and download the PDFs. A second parse method was created to go to the website links of each year and scrape and continue this process of downloading the PDFs.

In the settings file, we specified “pdf” to be the document format to save the files as. A download delay was also implemented. Without this, multiple threads will try to write to the csv file at the same time. This will produce a file lock error in the command prompt and no downloads.
import scrapy
from pic16bproject.items import Pic16BprojectItem
class courtscraper(scrapy.Spider):
name = 'court_spider'
start_urls = ['https://www.supremecourt.gov/opinions/slipopinion/20']
def parse_start_url(self, response):
return self.parse(response)
def parse(self, response):
cases = response.css("td a")
pdfs = [a.attrib["href"] for a in cases]
prefix = "https://www.supremecourt.gov"
pdfs_urls = [prefix + suffix for suffix in pdfs]
for url in pdfs_urls:
item = Pic16BprojectItem() #define it items.py
item['file_urls'] = [url]
yield item
def next_parse(self, response):
next_page = response.css('div.col-md-12 a::attr(href)').extract() #do i need [0]^M
yield scrapy.Request(next_page, callback=self.next_parse)
OCR and Text Cleaning
After downloading the opinion PDFs from the website using the scrapy spider, we will do the following:
- For each opinion, convert pages into jpg files
- Use OCR package to recognize the letters in the images and turn them into paragraphs of text
- There is a significant chunk of regular expression in the middle that cleans the text, gets rid of filler headers, syllabus pages, appendix etc
- Finally check if the resulting text fits a certain format. If it does, append the opinion info (Author, Text, Opinion Type) into the designated pandas data frame (which we will use for the remainder of the project). If the format does not match (special reports), we omit them.
- If the conversion is successful, the PDF will be automatically deleted. If te latter case, a message will be shown and the user can manually check out both the raw PDF and the converted txt file.
For every opinion PDF (downloaded from spider)
for op in [i for i in os.listdir("./opinion_PDFs") if i[-3:] == 'pdf']:
# *** Part 1 ***
pages = convert_from_path("./opinion_PDFs/" + op, dpi = 300)
image_counter = 1
# Iterate through all the pages in this opinion and store as jpg
for page in pages:
# Declaring filename for each page of PDF as JPG
# For each page, filename will be:
# PDF page 1 -> page_1.jpg
# ....
# PDF page n -> page_n.jpg
filename = "page_"+str(image_counter)+".jpg"
# Save the image of the page in system
page.save(filename, 'JPEG')
# Increment the counter to update filename
image_counter = image_counter + 1
image_counter = image_counter - 1
# *** Part 2 ***
# Creating a text file to write the output
outfile = "./opinion_txt/" + op.split(".")[0] + "_OCR.txt"
# Open the file in append mode
f = open(outfile, "w")
# Iterate from 1 to total number of pages
skipped_pages = []
print("Starting OCR for " + re.findall('([0-9a-z-]+)_', op)[0])
print("Reading page:")
for i in range(1, image_counter + 1):
print(str(i) + "...") if i==1 or i%10==0 or i==image_counter else None
# Set filename to recognize text from
filename = "page_" + str(i) + ".jpg"
# Recognize the text as string in image using pytesserct
text = pytesseract.image_to_string(Image.open(filename))
# If the page is a syllabus page or not an opinion page
# marked by "Opinion of the Court" or "Last_Name, J. dissenting/concurring"
# skip and remove this file; no need to append text
is_syllabus = re.search('Syllabus\n', text) is not None
is_maj_op = re.search('Opinion of [A-Za-z., ]+\n', text) is not None
is_dissent_concur_op = re.search('[A-Z]+, (C. )?J., (concurring|dissenting)?( in judgment)?', text) is not None
if is_syllabus or ((not is_maj_op) and (not is_dissent_concur_op)):
# note down the page was skipped, remove image, and move on to next page
skipped_pages.append(i)
os.remove(filename)
continue
# Restore sentences
# Restore sentences
text = text.replace('-\n', '')
# Roman numerals header
text = re.sub('[\n]+[A-Za-z]{1,4}\n', '', text)
# Remove headers
text = re.sub("[\n]+SUPREME COURT OF THE UNITED STATES[\nA-Za-z0-9!'#%&()*+,-.\/\[\]:;<=>?@^_{|}~—’ ]+\[[A-Z][a-z]+ [0-9]+, [0-9]+\][\n]+",
' ', text)
text = re.sub('[^\n]((CHIEF )?JUSTICE ([A-Z]+)[-A-Za-z0-9 ,—\n]+)\.[* ]?[\n]{2}',
'!OP START!\\3!!!\\1!!!', text)
text = re.sub('[\n]+', ' ', text) # Get rid of new lines and paragraphs
text = re.sub('NOTICE: This opinion is subject to formal revision before publication in the preliminary print of the United States Reports. Readers are requested to noti[f]?y the Reporter of Decisions, Supreme Court of the United States, Washington, D.[ ]?C. [0-9]{5}, of any typographical or other formal errors, in order that corrections may be made before the preliminary print goes to press[\.]?',
'', text)
text = re.sub('Cite as: [0-9]+[ ]?U.S.[_]* \([0-9]+\) ([0-9a-z ]+)?(Opinion of the Court )?([A-Z]+,( C.)? J., [a-z]+[ ]?)?',
'', text)
text = re.sub(' JUSTICE [A-Z]+ took no part in the consideration or decision of this case[\.]?', '', text)
text = re.sub('[0-9]+ [A-Z!&\'(),-.:; ]+ v. [A-Z!&\'(),-.:; ]+ (Opinion of the Court )?(dissenting[ ]?|concurring[ ]?)?',
'', text)
# Remove * boundaries
text = re.sub('([*][ ]?)+', '', text)
# Eliminate "It is so ordered" after every majority opinion
text = re.sub(' It is so ordered\. ', '', text)
# Eliminate opinion header
text = re.sub('Opinion of [A-Z]+, [C. ]?J[\.]?', '', text)
# Separate opinions
text = re.sub('!OP START!', '\n', text)
# Write to text
f.write(text)
# After everything is done for the page, remove the page image
os.remove(filename)
# Close connection to .txt file after finishing writing
f.close()
# Now read in the newly created txt file as a pandas data frame if possible
try:
op_df = pd.read_csv("./opinion_txt/" + op.split(".")[0] + "_OCR.txt",
sep = re.escape("!!!"), engine = "python",
names = ["Author", "Header", "Text"])
op_df.insert(1, "Docket_Number", re.findall("([-a-z0-9 ]+)_", op)[0])
op_df["Type"] = op_df.Header.apply(opinion_classifier)
# Lastly add all the opinion info to the main data frame
opinion_df = opinion_df.append(op_df, ignore_index = True)
os.remove("./opinion_PDFs/" + op)
print("Task completed\nPages skipped: " + str(skipped_pages) + "\n")
except:
print("Error in CSV conversion. Pages NOT added!\n")
print("-----------------------\nAll assigned OCR Completed")
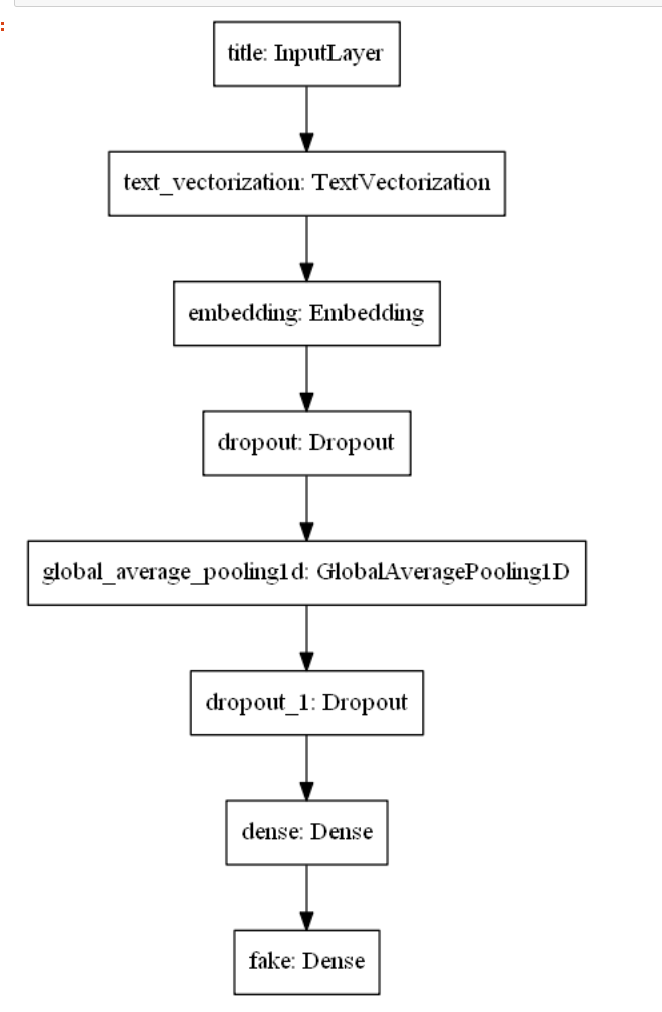
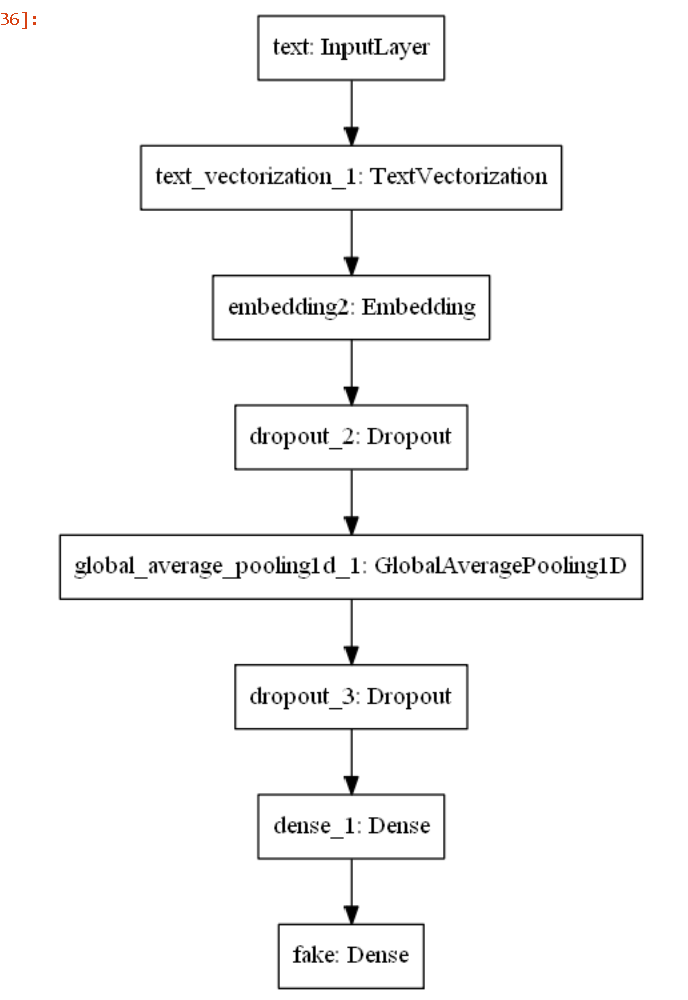
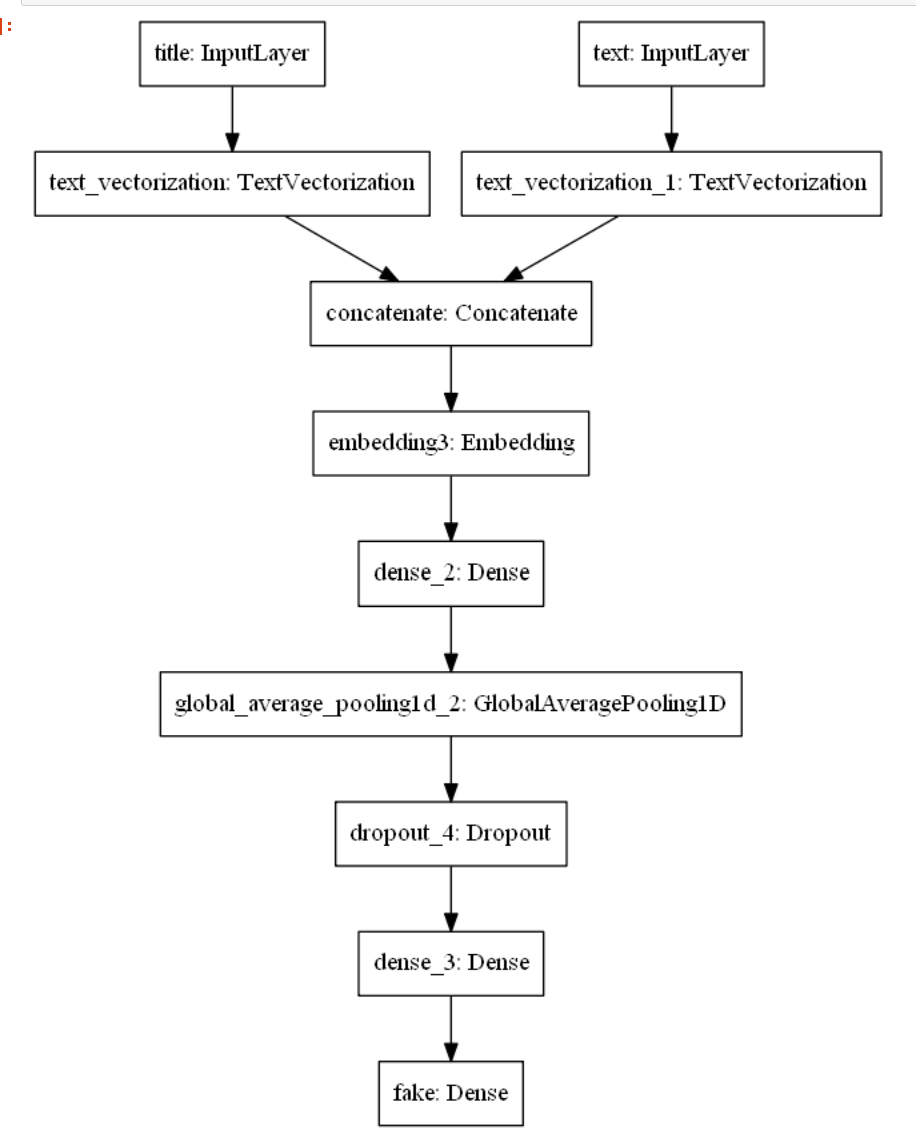
Type and Author Classification
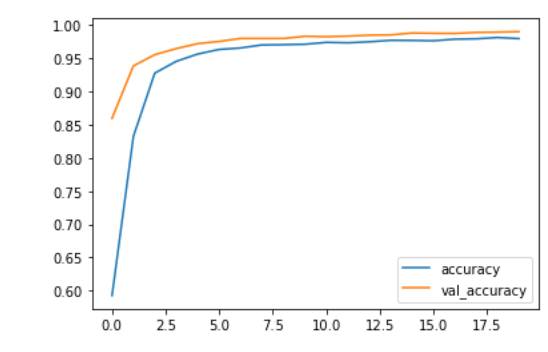
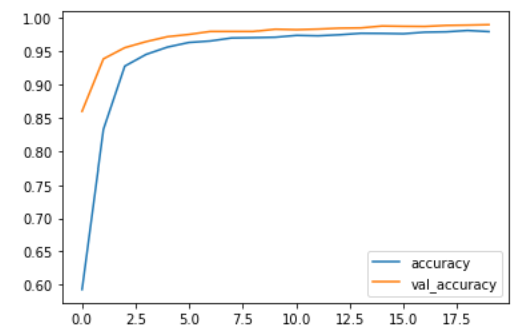
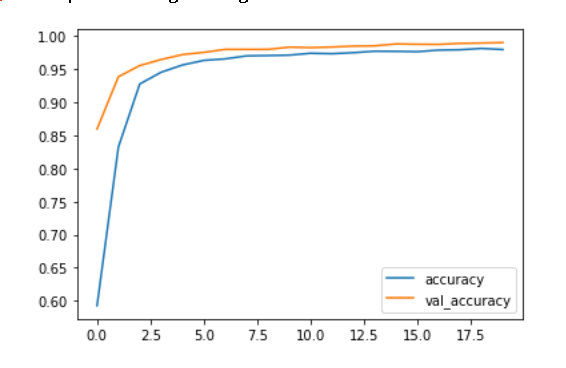
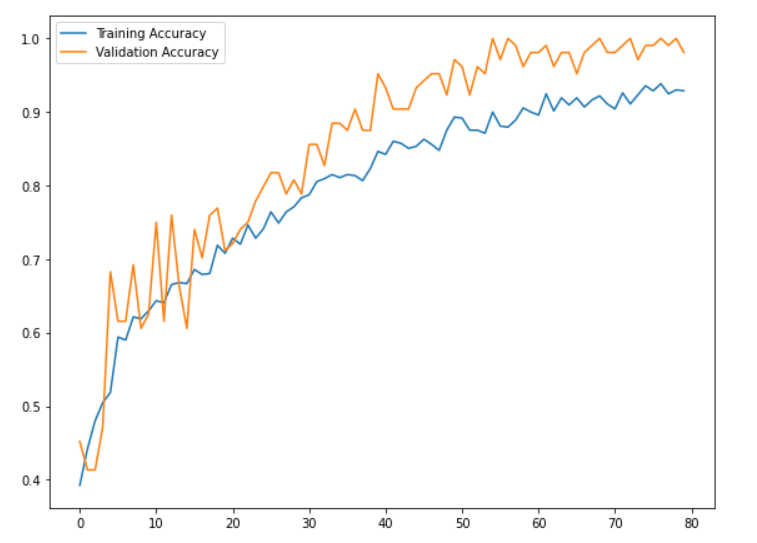
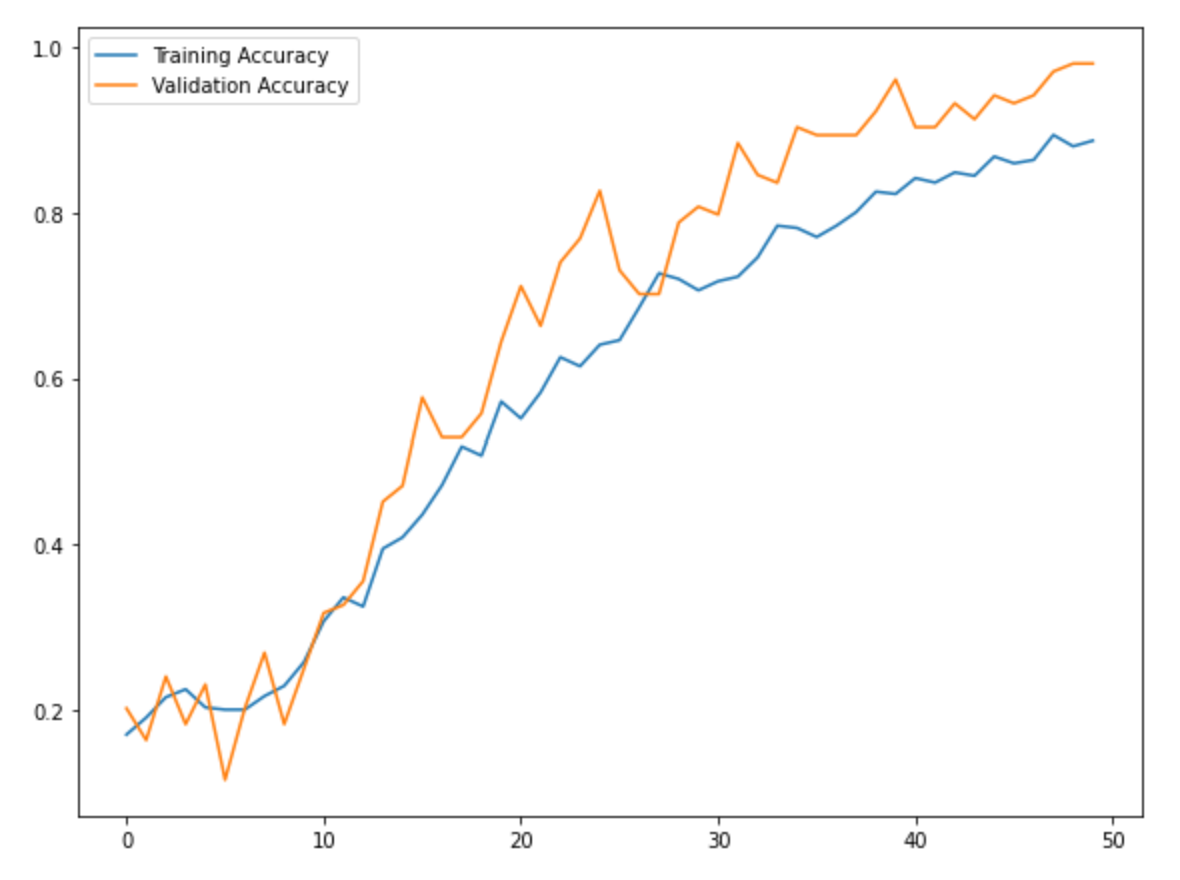
We used tensorflow in order to classify all of the opinion types and justices, labeled as authors, based on the text alone. To do this, we created two data frames: one with type and text as the columns, and another with author and text as the columns. Then, we converted each type and column into integer labels using a label encoder in order to move forward with our classification task. We split our data into 70% training, 10% validation, and 20% testing in order to train our models and compare our resulting accuracies,. Both the type and author models implemented a sequential model that used an embedding layer, two dropout layers, a 1D global average pooling layer, and a dense layer. The dimensions for the output and dense layer were altered based on the total number of opinion types (4) and total number of authors (12). We experienced great success with the training and validation accuracies for both models. For the type model, the training accuracies hovered around 92% and the validation accuracies settled around 99% as the later epochs were completed. For the author model, the training accuracies hovered around 87% and the validation accuracies settled around 97% as the later epochs were completed. Further, we did not worry too much about overfitting as there was a large amount of overlap between training and validation accuracies and there was never too much of a dropoff between the two. After training our models, we evaluated them on the testing set which was the random 20% of the original data. Once again, experienced great success as the type and author test accuracies were ~99.5% and ~95.6%, respectively. Thus, our models performed very well on the original dataset. However, we also created an additional testing set that included unseen data from the past two months alone. This is where our models seemed to falter. pecifically, our type model testing accuracy was ~28.1% and our author model testing accuracy was ~3.1%. These are clearly much lower than the testing accuracies from our initial data. Thus, we performed further evaluation of our datasets and noticed some variations. Specifically, the unseen test set which has all the data from the last two months, consisted of fewer authors than our original data. So, we removed the justices from the original dataset who were not seen in the data from the last two months and retrained and tested our models once again. Similar to the first time, the training and validation accuracies were very high. However, we did notice a slight increase in our testing accuracies as the type model improved to ~34.4% and our author model improved to ~15.6%. Although these are still rather low, we believe that further inspection into our test dataset would provide us with more clarity about potential improvements that we could make to our model so that it performs better with the testing data.
le = LabelEncoder()
train_lmt["Type"] = le.fit_transform(train_lmt["Type"])
type_df = train_lmt.drop(["Author"], axis = 1)
type_df
type_train_df = tf.data.Dataset.from_tensor_slices((train_lmt["Text"], train_lmt["Type"]))
type_train_df = type_train_df.shuffle(buffer_size = len(type_train_df))
# Split data into 70% train, 10% validation, 20% test
train_size = int(0.7*len(type_train_df))
val_size = int(0.1*len(type_train_df))
type_train = type_train_df.take(train_size)
type_val = type_train_df.skip(train_size).take(val_size)
type_test = type_train_df.skip(train_size + val_size)
opinion_type = type_train.map(lambda x, y: x)
vectorize_layer.adapt(opinion_type)
train_vec = type_train.map(vectorize_pred)
val_vec = type_val.map(vectorize_pred)
test_vec = type_test.map(vectorize_pred)
type_model.compile(loss = losses.SparseCategoricalCrossentropy(from_logits = True),
optimizer = "adam",
metrics = ["accuracy"])
type_model.summary()
Concluding Remarks
I am very satisfied with the outcome of our project. This project helped me understand a lot more about web scraping in particular. This was my first time conducting a sentiment analysis and it was interesting to see all the steps we needed to take in order to achieve a sentiment analysis. With more time, we would look into why the model performed better with the 20% test data set from the main data frame but performed significantly less accurately than the true test data.